
있었던 일
- 다 같이 코드 리뷰도 하고, 이 하나의 코드가 어떤 역할을 하는지도 알아볼정도로 세세하게 코드 분석을 해봤어
- 맨날 배우고 까먹고 반복하던 attention과 transformer를 좀 더 확실하게 내것으로 만들 수 있었어
공부한것
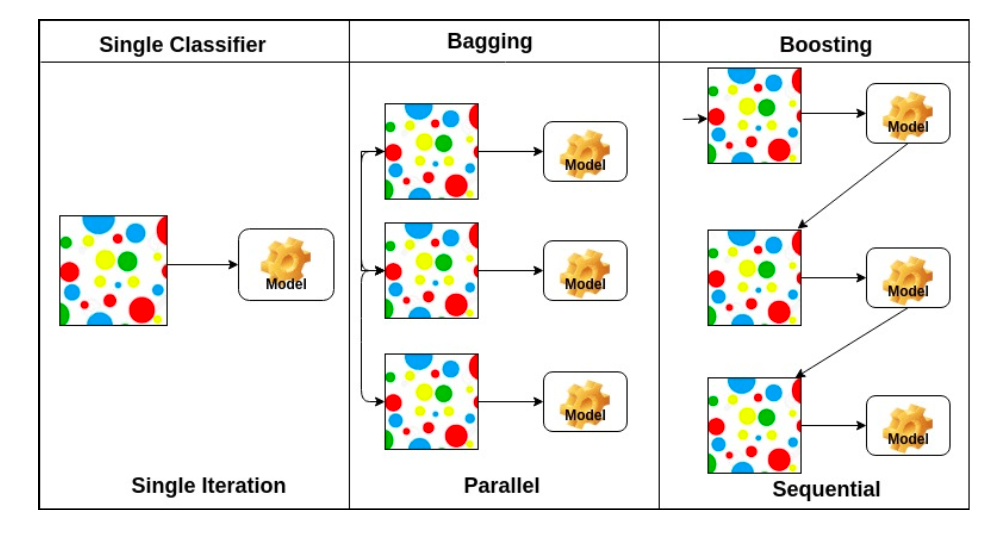
bootstraping : 정해진 데이터 내에서 임의의 random sub sampling을 하여 모델을 만들고 여러 모델들을 가지고 합쳐서 임의의 metric을 하는 방법
data preprocessing : zero-centering, normalization. gradient가 같은 부호로 나오는것과 같은 상황을 막기 위해 데이터를 정규분포화 시키는것. weight의 작은 변화에 덜 민감해진다. optimize가 더 쉬워진다.
np.dot : 차원이 맞지 않는 곱도 가능하다. 예를들어 2차원 행렬과 1차원 배열의 곱이 가능하다.
recurrent neural network :
결국 풀어서 보면 긴 웨이트 곱과 같다. 이때 sigmoid를 쓰면 결국 기울기가 소실되게 되고, relu를 쓰면 기울기가 폭발 해버리는 문제가 있다.
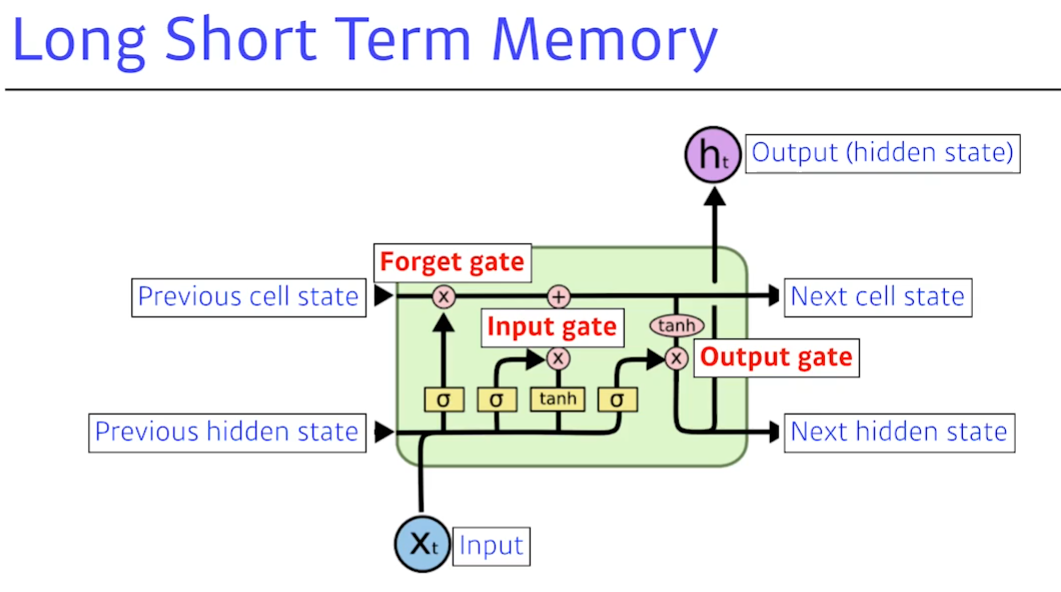
rnn에서 모든 층이 fc layer로 이루어져서 소실되거나 폭발하는 문제를 해결하려고 함. cell state를 추가했음
long short term memory : 가장 크게 봐야할것은 3가지의 gate이다. core idea는 중간에 흘러가는 cell state이다. 이것은 time step t까지 흘러 들어오는 정보를 요약한다.
forget gate : 현재 입력 정보와 hidden state를 토대로 cell state에서 어떤 정보를 버릴지 선택한다.
input gate : cell state에 어떤 정보를 올릴지 정한다. sigmoid는 어떤 정보를 올릴지 버릴지 판단. hyperbolic t 는 cell state에 추가될 후보이다. 이것을 gate에서 잘 조합해서 cell state에 추가한다.
output gate : 어떤 정보를 출력으로 내보낼지 현재 입력과 hidden state를 기준으로 cell state에서 선택한다.
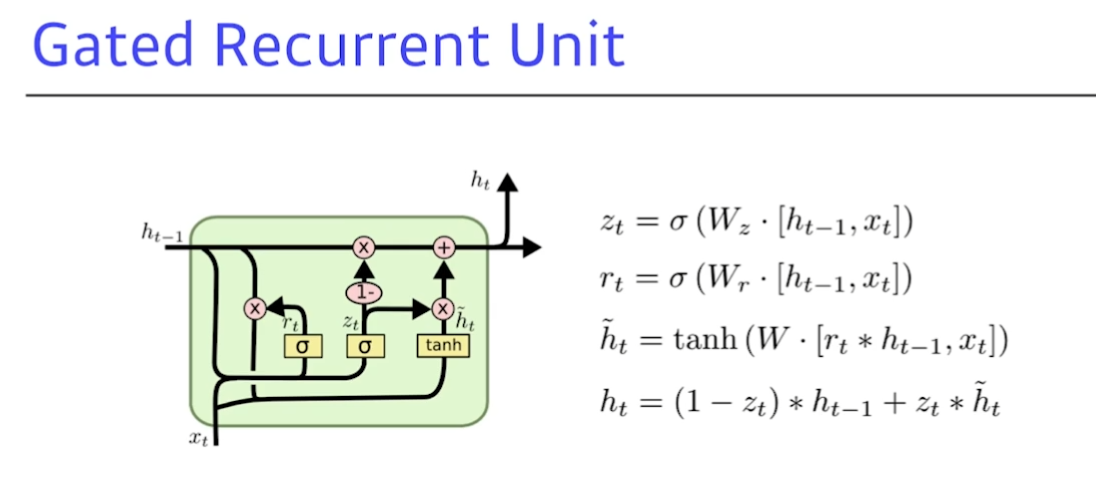
GRU : gate가 하나 줄고, cell state 없이 hidden state만 있다.
attention :
입력들 사이간에 유사도를 구하여 새로운 형태의 representation을 나타내려고 한다. attention은 (Q, K, V)의 형태이다.
Q : query(문의), K: key(비교), V:value(크기). seq-to-seq 모델에서는 decoder단의 hidden state들이 q이고 encoder단의 hidden state들이 k와 v이다. q와 k는 내적을 해야하므로 차원이 같아야 하지만 value는 그럴필요 없다.
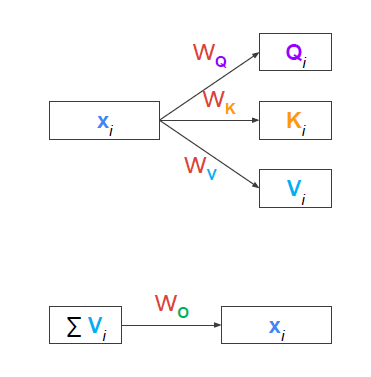
attention과 transformer와의 차이는 q, k, v 만들때 weight parameter가 사용된다는 것이다. 즉 hidden state 자체를 q, k, v로 활용하는게 아니라 입력된 input을 positional encoding 등과 같은 embedding 벡터로 만든후 파라미터 행렬을 곱하여 새로운 형태로 만들어준다. 그리고 나중에는 다시 입력과 같은 원상태로 돌아가게 만들기 위해 W_o가 필요하다
attention은 메커니즘이고, transformer는 그 메커니즘을 사용한 모델이다.
transformer :
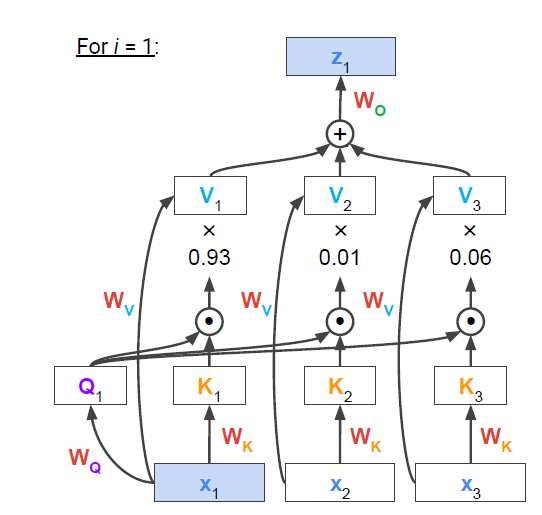
q와 k사이 내적을 통해 유사도 행렬을 구하고 이것을 이용해 value들의 가중합으로 표현한 z를 구한다. 이것은 문장 내에서 한 단어와 다른 단어들 사이의 연관성을 반영하여 새로운 vector를 만드는 행위다. 다르게 표현하자면 input token 들 사이 의미를 contextualize 하여 새로운 representation learning을 표현한다고 한다.
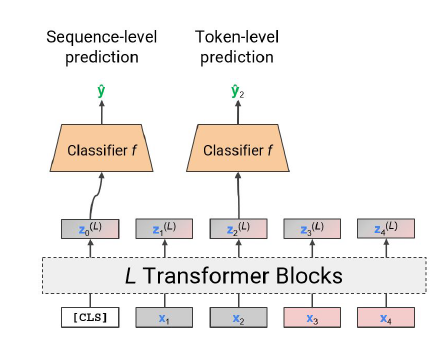
token aggregation :
위 그림처럼 나온 각각의 Z_i에 대해서 평균값을 취해서 모으는 방법도 있고, 더미 input token을 넣어 나오는 Z_0 을 사용하는 경우도 있다. 이때 Z_0은 더미 데이터와 나머지 input data들 사이 유사도만 보여줌으로 모든 토큰에 depend 되는 gloabal한 representation만 보여준다. 즉 문장 전체의 의미를 내포하고 있다.
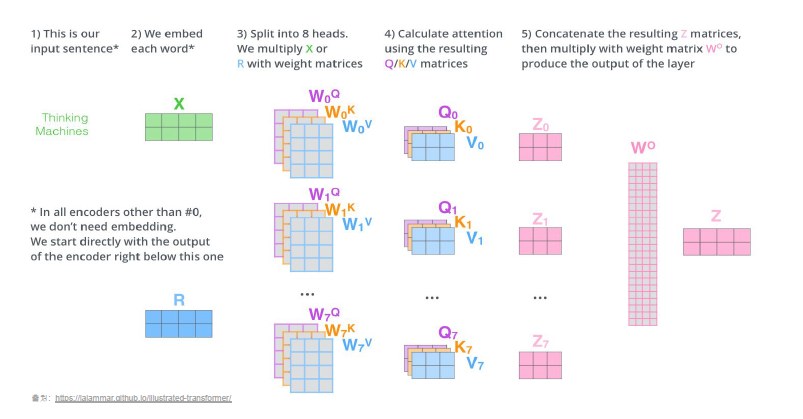
multi head attention은 입력 x의 차원이 (batch_size, seq_length, hidden_size) 일때 hidden_size를 쪼개서 (batch_size, seq_length, num_head, attention_size)로 바꿔준다. 이렇게 하는 이유는 병렬처리에 의한 속도 상승겸, 토큰이 한 단어에만 유사도를 가지지 않게 방지하는것이다.
이것은 head 갯수만큼의 Q, K를 만들고 이것을 재구성해서 나온 Z들을 나중에 concatenating 해서 W_0와 곱해줘서 다시 입력크기와 같은 z를 만들어준다.
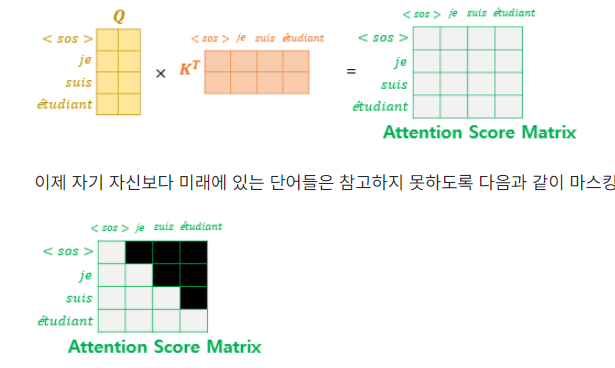
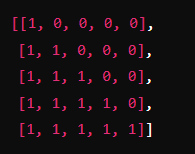
트랜스포머는 문장 행렬로 입력을 한 번에 받으므로 현재 시점의 단어를 예측하고자 할 때, 입력 문장 행렬로부터 미래 시점의 단어까지도 참고할 수 있는 현상이 발생한다. 이를 막기위해 트랜스포머의 디코더단에서의 첫 마스크드 어텐션은 query와 key사이 내적을 통해 구한 attention value에 현재 번역할 단어 이후에 나올 단어들을 참고하지 못하게 한다.
VIT :
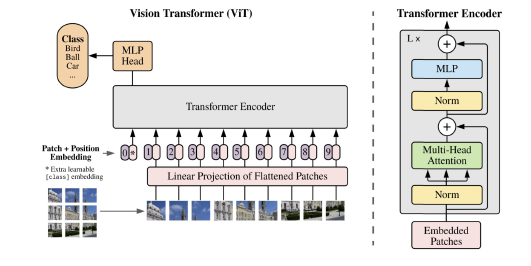
비전에 트랜스포머를 활용하는 방법이다. 입력할 이미지를 n*m 개의 패치로 쪼깨서 순차적으로 트랜스포머 입력으로 넣어준다. 이때 아까처럼 더미 데이터를 하나 더 넣어줘서 이미지 전체를 대표하는 하나의 임베딩 벡터를 만든다. 그리고 이것을 활용해서 분류 task처럼 사용할 수 있다.
cnn의 inductive bias와 같은 성질이 없으므로 순전히 데이터상에서 특성을 학습해야한다. 그러나 많은 학습 데이터가 제공되면 그러한 bias로부터 오는 spatial locality를 넘어서는 복잡한 모델링이 가능해서 성능이 더 좋게 나올 수 있다.
느낀것
- 기존 내가 공부했던것들이 얼마나 빈약했는지 느낄 수 있었어
- 공부하는게 이런 방법론이구나 대충 이해하고 넘어가는게 아니라 그 이해한 시간만큼 코드에 더 투자해야한다고 느꼈어
- 갑자기 트랜스포머가 나와서 진도가 빠르다고 느껴졌어
- 줌에서만 보던 친구들 오프라인에서 보니까 재미있었다!